






Turning big data into actionable business intelligence is a challenge clouded by fragmented infrastructures and data siloes. What’s the silver bullet?
Before the advent of miniaturized connected sensors and smart devices, the struggle to collect real-time data was expensive and unproductive. A decade before that, the Internet had already created an explosion of data which led to massive data management challenges that cloud computing resolved … sort of.
Today, while the Internet of Things, Wi-Fi 6 and 5G promise to make data collection more ubiquitous and accessible, the huge volumes of data generated still requires analysis offsite—an inefficient, laggy process unless you opted for edge computing and dedicated private cloud solutions.
While cloud computing has somewhat democratized storage of big data, the proliferation of disparate cloud platforms alongside legacy infrastructures and hybrid-platform services has actually created huge data lakes we can safely call silos.
What we all want from data
Knowledge is power, and absolute data is the foundation of relevant, actionable knowledge.
In the age of digital transformation, data collection has to be done in real-time, cleaned and integrated with other relevant data pools intelligently, and then processed for insights that aid in business intelligence (BI). Great BI can then power great marketing and sales, eventually leading to great all-round business relationships and ultimately, MONETIZATION.
In order to milk data for its power, we have to ensure it is relevant, accurate and thorough. In computing terms, for data to be made usable, issues such as capacity planning (for storage needs), resource contention (managing limited computing resources) and sanitization (to transform raw data into a useful format) need to be addressed and synchronized seamlessly.
The reality is that:
- huge volumes of data require huge expenses to store before they can be processed.
- data loading challenges result in sub-optimal data management.
- lakes of data end up untapped or underutilized when new lakes of incoming data continue to eat up storage and resources.
- by the time such huge lakes of piled-up siloed data get processed, they may have already lost some of their currency or intrinsic message.
The rise of cloud-native data warehousing
The cloud hanging over big-data management and its integration into digital transformation processes is not inherently a cloud problem at all, because the concept of cloud computing embodies unified, simplified, ubiquitous and connected processing of information.
Rather, the hurdles to data monetization have been a result of cautious, tentative adoption of cloud computing—leading to fragmentation of markets and complexities in adoption. It took cloud computing almost two decades to reach its current level of maturity, and the delay has inevitably led to too many competing solutions for equally-many legacy concerns about adopting hybrid or multicloud infrastructures.
So, what solution can help enterprises at various levels of digital transformation in a data-hungry post-COVID19 world to navigate through all the cloud-adoption complexities and straight into the business of monetizing data?
- Cutting to the chase would logically involve a turnkey cloud-native solution that serves to consolidate all siloed data lakes (physical and cloud-based) into a centralized warehouse, and do its work from that efficient single source of data. An ideal cloud-native warehouse must also take care of the data loading and data integration problems economically.
- Once the lakes of information are cleaned up and integrated, data analytics can proceed without hindrance. According to cloud data platform company Snowflake, “a true cloud data warehouse is delivered as software-as-a-service (SaaS), offering unlimited scalability up, down and out (concurrency) on demand. Scaling in either direction is effortless but only if warehouse compute and storage resources are truly separate. In addition, there must be a third, sophisticated metadata layer that orchestrates all of the work.”
- With this type of architecture, corporates can choose any-size compute cluster to handle any query, data loading or dev/test job, and they are not compelled to dump data from a tightly coupled compute node before resizing. This also means businesses can scale down the compute power when a job is done, paying only for what is used.
- By separating compute from storage, a cloud data warehouse lets all users access the same, single copy of the data simultaneously. This eliminates the chance of data inconsistency, which occurs when multiple user groups copy the same data to data marts to speed query performance but use different rules.
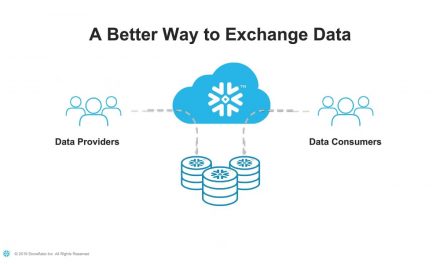
- Once the data has finally been processed, it can be marketed or shared with other organizations containing unique data. This is data exchange, and this is where monetization begins.
- When centralized cloud-based repositories of ready-to-use data are mutually exchanged, organizations save a lot of time and money sourcing for the information themselves. That information can yield new insights and collaborative opportunities that enrich the collective business intelligence and result in a win-win scenario for all stakeholders, including global customer bases.
- How does this monetization of data work? One example: a data service company that gathers mobile phone location information and usage data can share the anonymized information with advertising agencies and marketing groups so they can execute highly targeted campaigns to specific consumers.
It is clear that enterprises that are stuck in a rut with their current data management challenges can consider turning to a cloud data platform to cut the learning curve. Various solutions already exist that can meet different corporate mandates regarding data strategies and visions.
Rise of the data cloud
An evolutionary feature in cloud data platform, called the “data cloud”, has expanded the concept of “a single source of truth” to another level: a single platform for data marketing.
Basically, a data cloud would encompass an ecosystem where all customers of the cloud data platform can exchange ideas and opportunities related to data, as a springboard for not just data monetization but long-term corporate collaborations.
A recent case in point is Starschema, a popular and free COVID-19 data set that is curated and analytics-ready. People who gain access to this data can also offer related data sets about weather trends, to understand the impact that weather has on the coronavirus.
This kind of altruistic data sharing may well be part of the “new business normal” in the near future, where people can not only derive insights about commercial survival from data, but also learn to share useful data freely for global benefit.












{kind=link}